안녕하세요, 이번 포스팅에서는 지난 강좌에서 배웠던 사용자 정의 함수 개념의 심화적인 내용을 배울 것입니다.
바로 "재귀함수"라는 것인데요, 오늘 이것을 배우는 이유와 그 개념에 대해서 살펴보고자 합니다.
step by step으로 차근차근 따라오시면 어렵지 않을 것입니다.
| 재귀란 무엇인가?
우선 재귀함수의 '재귀'라는 단어의 의미를 알아보겠습니다.
컴퓨터 과학에 있어서 재귀(再歸, Recursion)는 자신을 정의할 때 자기 자신을 재참조하는 방법을 뜻하며, 이를 프로그래밍에 적용한 재귀 호출(Recursive call)의 형태로 많이 사용된다. 또 사진이나 그림 등에서 재귀의 형태를 사용하는 경우도 있다. - 위키백과
위키백과에서 가져온 재귀의 컴퓨터 과학 측면에서의 정의입니다.
쉽게 말해서, "재귀적으로 정의했다" 라는 말은 자기 자신을 정의할 때 자기 자신을 이용했다는 것입니다.
가령 5! (5 팩토리얼)을 정의할 때도,
5! = 5 * 4! 라고 나타낼 수 있으므로 이를 일반화하면
n! = n * (n - 1)!
라고 나타낼 수 있게 됩니다.
이 등식에서 팩토리얼을 정의하는데 있어서 팩토리얼을 사용했다는 것은, 재귀적 정의를 활용했다고 할 수 있는 것이겠죠.
| 재귀적 정의의 조건
어떤 개념을 재귀적으로 정의하기 위해서는 두 가지 Step이 필요합니다.
- Recursive step : 자기 자신을 호출하는 step
ex) n! = n * (n - 1)!
- Termination step : 재귀를 벗어나기 위한 step
ex) 0! = 1
여기서 Termination step, 즉 종료 조건이 매우 중요한데요, 위 예시에서 Recursive step만 존재할 경우
5! = 5 * 4!
4! = 4 * 3!
3! = 3 * 2!
2! = 2 * 1!
1! = 1 * 0!
0! = 0 * (-1)!
(-1)! = (-1) * (-2)!
.
.
.
이렇게 끝없는 재귀의 굴래에서 빠져나오지 못하게 됩니다.
그래서 Termination step을 0! = 1 로 정의해 줌으로써 팩토리얼의 재귀적 정의가 비로소 완성되는 것이죠.
| 프로그래밍에서의 재귀
그렇다면 프로그래밍 언어로 어떻게 재귀를 구현하는지 살펴보겠습니다.
바로 예제 코드를 보시죠.
#include<stdio.h>
int factorial(int k);
int main()
{
int result = factorial(5);
printf("result: %d\n", result);
return 0;
}
int factorial(int k)
{
if(k == 0)
return 1;
else
return k * factorial(k - 1);
}이 코드는 팩토리얼을 재귀함수로 구현한 것입니다.
한줄 한줄의 의미를 같이 해석해봅시다.
int factorial(int k);
이 문은 저번 포스팅에서 다루었었죠?
factorial 이라는 함수가 main 아래에 정의되어 있기 때문에 프로토타입을 선언해 주지 않으면 오류가 발생합니다.
int result = factorial(5);
그리고 result 변수에 factorial 값을 할당하는 문입니다.
이제 factorial의 실행 흐름을 봅시다.
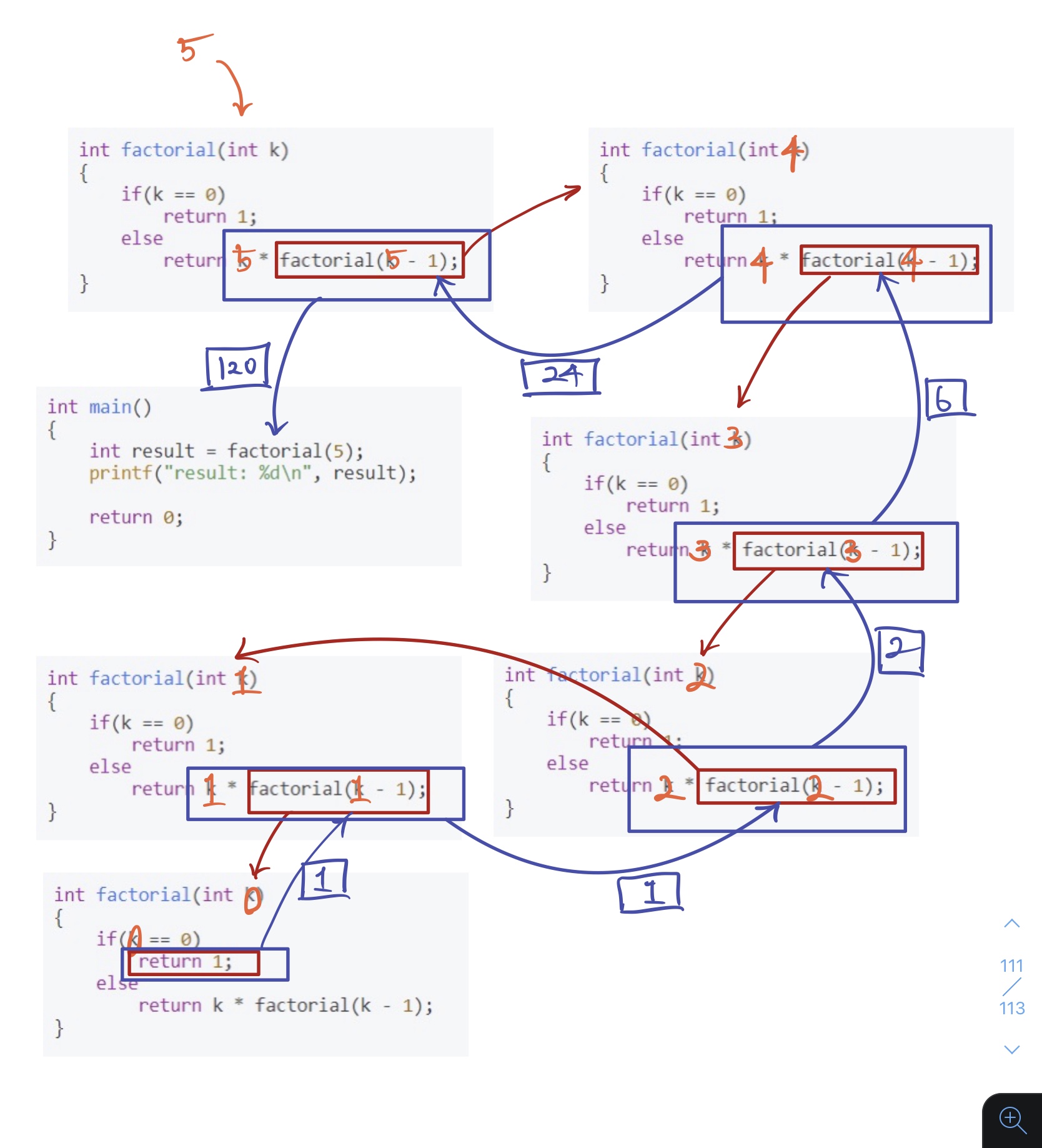
factorial 함수에 5가 들어갔을 때,
Depth1: <factorial(5)> 종료조건이 충족되지 않으므로 return 5 * factorial(4); / 값이 반환될 때까지 대기
Depth2: <factorial(4)> 종료조건이 충족되지 않으므로 return 4 * factorial(3); / 값이 반환될 때까지 대기
Depth3: <factorial(3)> 종료조건이 충족되지 않으므로 return 3 * factorial(2); / 값이 반환될 때까지 대기
Depth4: <factorial(2)> 종료조건이 충족되지 않으므로 return 2 * factorial(1); / 값이 반환될 때까지 대기
Depth5: <factorial(1)> 종료조건이 충족되지 않으므로 return 1 * factorial(0); / 값이 반환될 때까지 대기
Depth6: <factorial(0)> 종료조건이 충족되었으므로 return 1;
Depth5: return 1 * 1;
Depth4: return 2 * (1 * 1);
Depth3: return 3 * (2 * (1 * 1));
Depth2: return 4 * (3 * (2 * (1 * 1)));
Depth1: return 5 * (4 * (3 * (2 * (1 * 1))));
result = 5 * 4 * 3 * 2 * 1 * 1 = 120
이런 과정을 거쳐 우리가 원하는 값을 얻어내는 것입니다. 위의 사진과 같이 보시면 더 이해가 빠를 것 같습니다.
| 재귀함수를 왜 공부할까?
어떤 구조를 재귀적으로 표현하면 매우 간결한 느낌을 줄 수 있습니다. 하지만 프로그램 실행 과정도 그러할까요?
오히려 재귀적으로 구현한 로직보다 일반적인 반복문을 사용하여 구현하는 로직이 더 빠른 경우가 많습니다.
재귀가 결코 효율적인 알고리즘이 아니라는 말이죠.
조금 전에 살펴보았던 factorial 함수의 실행 흐름만 잘 생각해봐도 알 수 있습니다.
함수는 호출될 때마다, 그 안에서 정의되는 매개변수와 다른 변수들의 메모리를 할당하게 됩니다.
그런데 함수 안에서 자기 자신을 호출하게 되면, 그 안의 변수들을 다른 메모리 공간에 할당하고,
그 안에서 또 자기 자신을 호출하면, 또 그 안의 변수들을 메모리 공간에 할당하고 ... ...
결국 재귀 알고리즘에서 많은 Depth를 수행하게 되면 그만큼의 메모리가 누적된다는 것입니다.
하지만, 그럼에도 불구하고 재귀 알고리즘을 사용하는 이유는, 사람이 이해하기 쉽고 명쾌한 표현이 가능하기 때문입니다.
오늘 배운 재귀함수 부분을 익숙하게 사용하기 위해서는 많은 연습이 필요합니다. 또 나중에 자료구조를 배울 때에도 유용하게 사용 가능하니 충분히 연습하시면 좋을 것 같습니다.
이 포스팅의 내용이 유익하셨다면 공감 버튼과 댓글 달아주시고, 오류, 오탈자 등의 피드백 사항이나 질문 또한 댓글로 남겨주시면 감사하겠습니다.
'C언어 강좌' 카테고리의 다른 글
| [C언어_15] C언어 문제 풀이 #5 (0) | 2020.11.22 |
|---|---|
| [C언어_13] 사용자 정의 함수, 프로토타입(Prototype) (0) | 2020.11.21 |
| [C언어_12] C언어 문제 풀이 #4 (0) | 2020.11.19 |
| [C언어_11] 2차원 배열과 메모리의 특성 (0) | 2020.11.15 |
| [C언어_10] 1차원 배열 & 배열을 이용한 문자열 처리 (0) | 2020.11.09 |

